attention种类
MHA
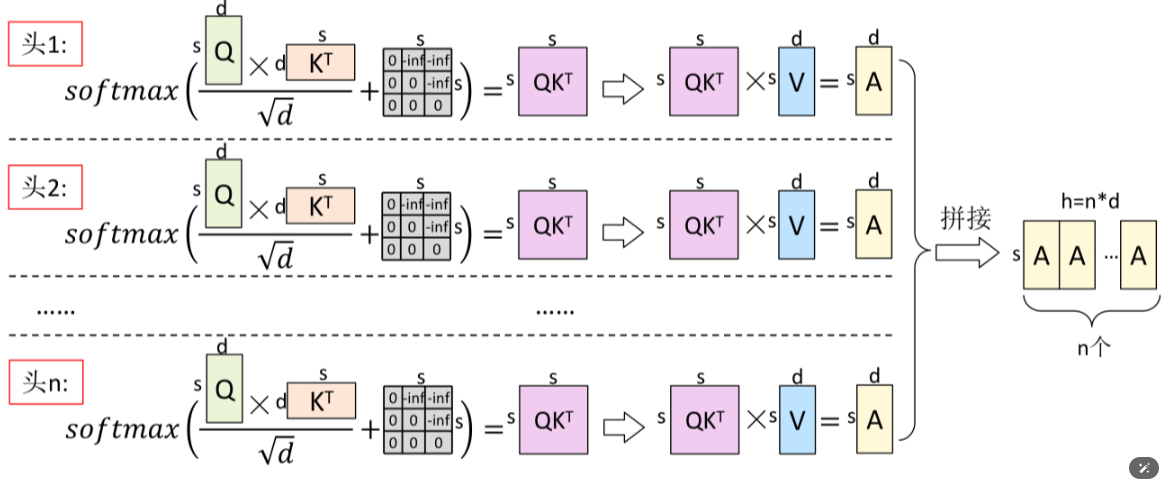
一图看懂Multi-HeadAttention
MQA
MHA kvcache的巨大开销,直接全部共享,损失推理的效果GQA


Paged Attention
首先说明一点paged attention只是一种attention中的kvCache管理方案,并不是新的attention计算方式。
Paged顾名思义是与操作系统中的分页管理有关系,paged attention就是将kvCache进行分页管理,至于为什么要进行分页管理就需要先回顾一下LLM中的kvCache的特点。
在首次prefill阶段,kvcache的大小是0,也就是输入到模型的是一个空的tensor,当然也可以不输入给模型(ps:这就需要模型支持不确定数量的输入节点,这在python代码中是很容易的,但是在端侧设备中多数是不支持可变数量的输入的),prefill阶段结束后会产生prefill输入的tokens数量+1个的kvCache,而每次输入的tokens数量并不固定,那么如何管理kvCache的内存呢?
- 静态分配? kvCache的大小是会不断增长的,静态分配是的大小设置为多少都不见得合适,太大了会占用过多内存,且可能出现大部分申请的内存并没有利用的情况,小了就不够多轮对话产生的kvcachekvcache存储。 (X)
- 动态分配?动态内存相对来说较为合适,但是从现存的操作系统的内存管理来看,内存碎片问题是一个很难解决的问题,这对于LLM推理来说也是一个麻烦,kvCache的大小会导致在多次对话后,没有合适的连续空间来分配给kvCache(碎片化的内存会影响这种连续分配的方式)
但是kvCache还有一个特点,在一个确定的模型中,大小只受限于sequence Length这一个维度,也就是输入tokens数+输出tokens数,这也就意味着如何以这个维度为单位来存储kvCache就可以完全确定每次存储的kvCache大小。
总结来说kvCache的特点如下:
- 理论上大小可能不存在上限
- 除了sequenceLength这个维度外全是固定shape
分页式管理方案
以Qwen2.5为例,kvCache的大小为
(decodeLayer, k&v, batchSize, numKVHead, sequenceLength, headDim)
e.g. (24, 2, 1, 2, x, 128)
那么这对于paged attention 来说就很容易表示存储关系了,分页式存储维护block table来管理虚拟内存和物理内存,虚拟内存中是连续分配的,而物理内存中可以是不连续分配的,而block table就是用来映射物理内存和虚拟内存关系的。每次分配一个block,一个block中可以存储多个kvCache,存储的kvCache数量为block size,因此以paged attention方式管理的kvCache的表达方式为
(numBlock, blockSize, deocdeLayer,k&v,batchSize,numKVHead,headDim)。
下图为两次sample同时请求时的管理方式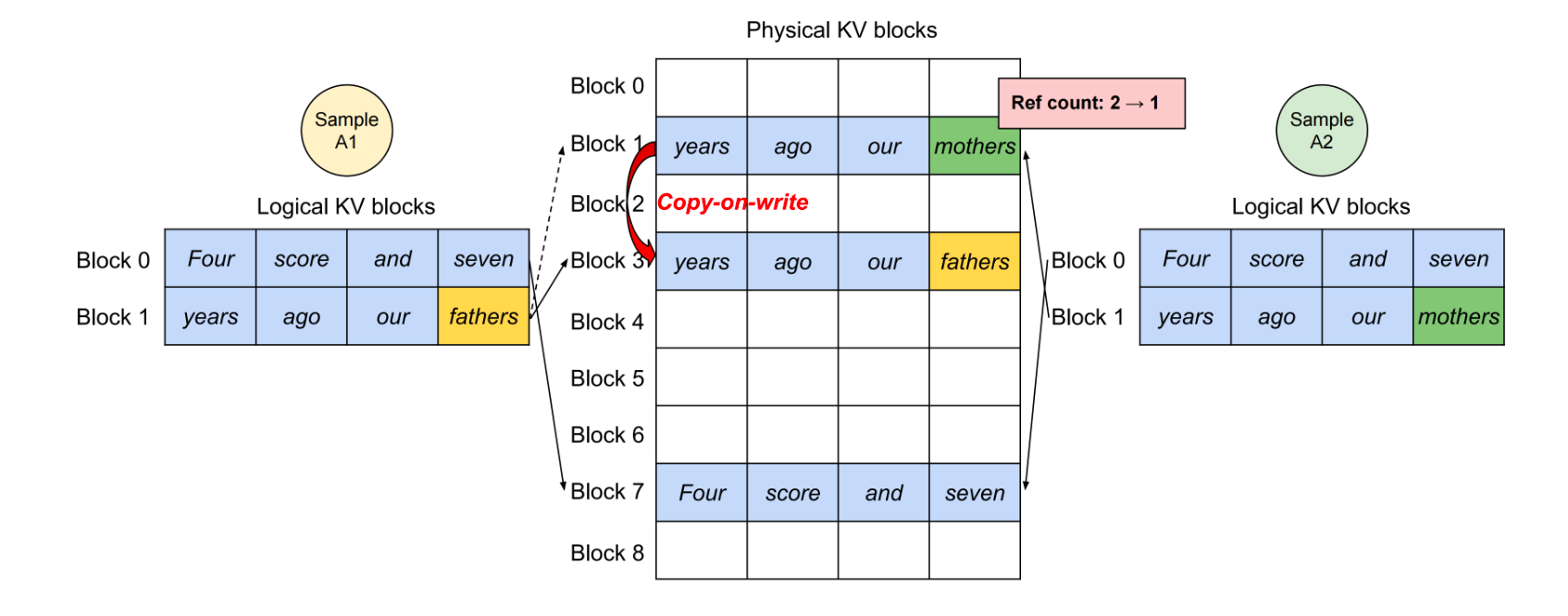
来源七月大佬csdn
首先每个用户都会对应一个logical kv block table,用于管理自己的kvCache,多个logical table会对应一个physical kv block table,这个物理table用于非连续存储kvCache。
其次,当多个用户的请求存在完全相同的内容时,会完全共用存储中的kvCache,这时也会有block的引用计数,例如block7
最后,当两个用户请求产生的token出现不同时,会触发复制相同token kvCache的机制,减少计算例如block1和3。
映射方式
这里就产生了一个问题,模型输入中如果只有logical table,那怎么知道这个逻辑表对应的物理表中的位置呢,这就需要一个新的属性来表示,称为slot mapping。
这个slot mapping就是用来描述当前的这个作为输入的kvCache与物理设备的映射关系,数据结构通常就是一个list[N],将logical table [0-n]映射到physical table[list[N]] 上。
且并不一定logical 的最后一个block会被填满, 因此还需要一个参数来表明最后填充的数量。
1 | slot mapping: list[int] |
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



